Матрикснет
Матрикснет – это алгоритм машинного обучения, разработанный в Яндексе и внедренный в 2009 году. Представляет собой градиентный бустинг на симметричных (oblivious) деревьях решений. Он используется не только для построения формулы, ранжирующей поисковую выдачу, но и для множества других задач: предсказание кликов на рекламу, обнаружение ботов, разрешение омонимии и даже определения размера вознаграждений сотрудникам. Алгоритм устойчив к переобучению, позволяет гранулированно настраивать полученную формулу (так, чтобы изменения в оценке одного класса объектов не оказывали влияние на оценку другого класса объектов). Летом 2017 года ему на смену пришел алгоритм CatBoost, поддерживающий обработку категориальных признаков.
В чем заключается принцип работы матрикснет
Алгоритм матрикснет, по всей видимости, натравливается разработчиками на сайты, которые были высоко оценены асессорами, и на них учится вычленять какие-то незаметные взгляду человека факторы, которые свидетельствуют о высоком качестве сайта. Специалисты из Яндекса утверждают, что матрикснет позволяет корректировать формулу ранжирования сайта, делая выдачу более качественной для пользователя, на основании оценки меньшего числа сайтов, нежели требуется другим алгоритмам. Также утверждается, что количество оценок асессоров для корректной работы алгоритма матрикснет не увеличено по сравнению с другими алгоритмами. В компании Яндекс утверждается, что алгоритм матрикснет может корректировать алгоритмы ранжирования для каких-то областей. То есть определять факторы, специфические для, например, музыкальной сферы и включать их в формулу расчета сайтов, касающихся музыки. Тем самым конечный пользователь получает более точную выдачу по всем музыкальным запросам, но при этом такое специфическое вмешательство никак не затрагивает другие области. Например, если пользователь хочет послушать музыку, то логично выдавать ему вначале сайты, на которых композиции представлены в хорошем качестве (если о них вообще представлена информация). Но хорошее качество аудио файлов является специфичным для запросов по музыкальной теме. Если пользователь хочет почитать книжку или найти информацию про компьютеры, то качество аудио файлов на сайте учитываться поисковиком уже не будут.
Итак, это алгоритм, работающий уже пять лет, который позволяет более точно ранжировать сайты, используя меньшую выборку сайтов для самообучения. Этот алгоритм также позволяет настроить формулу расчета индекса для какой-то отдельной области, не затрагивая при этом остальных. Приведем официальную информацию от Яндекса. В нижеприведенном видео это начинается на 10-й секунде 15-й минуты.
«На самом деле Матрикснет – это целая совокупность различных методов машинного обучения, но все они так или иначе используют алгоритм под названием Gradient Boosted Regression Trees (GBRT)».
Кроме того, про Матрикснет хорошо и подробно было рассказано в феврале 2017 года.
Матрикснет – это «целая совокупность разных методов машинного обучения, но все они так или иначе используют алгоритм под названием Gradient Boosted Regression Trees (GBRT)», по официальной информации Яндекса на август 2016 года. Матрикснет был выпущен в 2009 году. «Что это такое? Это множество решающих деревьев, которые подобраны таким образом, чтобы суммируя значения в листьях этих деревьев, мы бы получили хорошее предсказание оценки релевантности, которую поставил ассесор. В узлах дерева расположены разделяющие условия, которые представляют собой приблизительно такое: фактор №50 больше, чем 0,5 или меньше? Если больше, то мы идем налево, а если меньше, то направо. И строим такие вот деревья глубиной чуть больше, чем на рисунке, и в листьях такие числа подбираем, что если множество таких деревьев просуммировать, мы бы получили хорошее предсказание ассесорской релевантности».

Уже в феврале 2017 года появилась более полная и более свежая информация. Подтвердилась информация о том, что матрикснет – это градиентный бустинг на деревьях решений. Оказалось, что он применяется в Яндексе практически повсеместно, даже в определении размеров денежных премий.

Еще раз про то, как выглядит суммирование деревьев решений

В Матрикснете используются не обычные, а так называемые oblivious-деревья решений. «Oblivious-дерево – это такое дерево, где на каждом уровне находятся разбиения по одному и тому же признаку и и одному и тому же числу». Почему используются именно такие деревья?
- Модель на таких деревьях оказывается устойчивой к переобучению: очень много таких деревьев можно сложить.
- Для вычисления листового значения нужно вычислить значения всех разбиений («сплитов»), значит не важно в каком порядке мы будем это делать. Это используется для оптимизации применения и обучения.
- «Oblivious-дерево эквивалетно табличке просто».

Рассмотрим, как велика формула ранжирования Яндекса: сколько в ней деревьев решений и сколько байт она занимает. Как видим, в настоящий момент в формуле суммируется более 70 000 деревьев решений, «весит» формула 840 мегабайт.

Что дает введение Яндексом матрикснета для пользователя
Пользователь, как и задумывалось, от этого выигрывает, поскольку получает более качественную выдачу. Также пользователь, задающий вопросы по каким-то узким сферам также доволен, поскольку алгоритм матрикснет занимается усовершенствованием формулы ранжирования не только широких и общих запросов, но и нишевых запросов по узким темам, так что все специалисты по коллекционированию лютневой музыки шестнадцатого века просто счастливы.
Вот иллюстрация возможности тонкой настройки матрикснета:
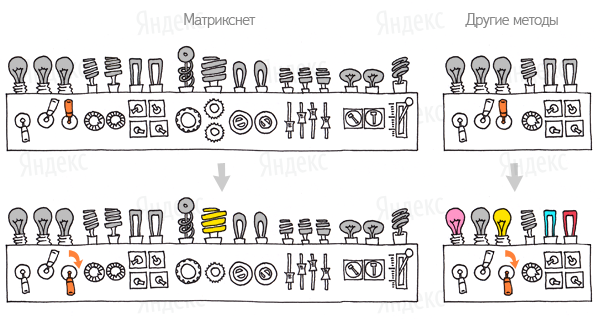
Матрикснет и seo. Какие можно сделать выводы для оптимизаторов
Итак, основные выводы, которые можно сделать из тех знаний о марикснете, которые сообщает Яндекс это то, что алгоритмы оценки постепенно превращаются в скайнет из просто анализаторов легкоманипулируемых внешних факторов продвижения сайтов во все более продуманному, детализированному ранжированию и оценке сайтов.
В сущности, это означает, что пора переходить к максимально честным и рекомендованным способам продвижения сайтов. Даже если Вы не знаете всего, что приведет к высоким местам в рейтинге, то главное помнить, что любой сайт – это площадка для того, чтобы доносить какую-то информацию до пользователя, а это значит, что сайт должен быть удобен пользователю и нести ему полезную информацию. Если Вы руководствуетесь этим принципом, то вероятность того, что Ваш сайт забанят приближается к нулю. Если же сайт сделан ради того, чтобы повесить кучу рекламы, содержит мало информации по теме, а вся информация – слегка переделанная копипаста из Википедиии или любых каких-нибудь других источников, то такой сайт очень быстро вылетит из индексации, его тИЦ обнулится и так далее и тому подобное. Сейчас одноходовки с раскручиванием сайта левым методом прокатывают все хуже и хуже, а через несколько лет вообще перестанут прокатывать.
Сейчас при раскрутке сайта и поднятии его в поисковой выдаче следует обращать и уделять внимание таким внутренним факторам как тексты статей. Они должны быть написаны энциклопедичным стилем, википедия-стайл, так сказать. Статьи должны подробно и с разных сторон раскрывать тот предмет, который они описывают. Поскольку развитие поисковых фильтров пошло по обучению их семантическому анализу текстов, то написание копирайтерских продающих, нахваливающих продукт статей не поможет. Это только потратит время, деньги, а пользы принесет, но не очень много. После того как статьи, охватывающие Вашу нишу, написаны и выложены, то они должны быть еще и пересосланы друг на друга. Это позволит поисковику продемонстрировать, что эти статьи покрывают определенную область, семантически связаны друг с другом и поэтому представляют ценность для пользователя. Также не должно получаться так, что все статьи рассчитаны на то, чтобы продвинуться по запросам, которые спрашивают более 1000 раз за месяц – так они не выйдут в топ, а поисковик решит, что Вы хотите его надуть. Поскольку в любой области есть известные вещи и неизвестные, а когда покрывают и описывают область, то логично предположить, что хотят рассказать обо всем, то и статьи, соответственно, будут в большей своей части рассчитаны на не самые популярные запросы, а только некоторые будут рассчитаны на популярные.
Итак, вот небольшой список того, на что следует обратить внимание:
- Качественные статьи
- Перелинковка
- Соотношение статей по ширине запроса. Это раскрывается более подробно здесь.
В качестве вывода можно посоветовать стараться делать честные нужные и интересные людям сайты.